공분산분석(analysis of covariance; ANCOVA)
공분산분석은 분산분석과 회귀분석이 결합된 형태의 분석법이다.
위 내용을 아래와 같이 구분하여 설명할 수 있다.
- 범주형 변수의 수준(level) 간에 종속변수의 평균에 차이가 존재하는가 를 분석한다 (ANOVA)?
- 여기에 종속변수에 영향을 미칠 것으로 판단되는 연속형 변수, 범주형 변수(공변량: covariate)의 효과를 동시에 고려하여 분석한다.
- 정리하면, 각 변수 안에서 공변량을 독립변수로 하는 회귀분석을 시행하고, 이것으로부터 얻어진 변수 간 회귀식을 분산분석한다.
공분산분석의 목적
- 공변량을 통제하여 독립변수의 순수한 영향을 검정하기 위함이다.
- ANOVA에 통제할 수 없는 연속형 변수를 통제하여 오차를 줄이고 검정력을 높인다.
공분산분석의 가정
정상출생아와 조산 출생아의 뇌 발달 차이를 검정하고자 할 때,
- 가설: 두 그룹간 백질 성숙도의 차이가 있을 것이다.
여기에, 우리는 백질의 분획이방성(fractional anisotropy; FA)에 순수하게 조산 출생의 여부가 미치는 영향을 보고 싶다. 그렇지만, 종속변수인 FA에 신생아의 재태 기간(Gestational age; GA) 혹은 MRI를 찍은 주수(Age at MRI; 신생아 뇌 발달은 급격하게 이루어 지기 때문에 MRI를 찍은 주수가 백질 발달에 영향을 충분히 미칠 수 있다)에 따라 FA가 영향을 받을 수 있다. 그렇기 때문에 우리는 GA와 Age at MRI를 종속변수 FA에 영향을 미칠 것으로 판단하여 covariate로 지정할 수 있다.
우리는 성별과 Age at MRI가 두 그룹의 FA에 동일하게 영향을 미치는가에 대하여 질문할 수 있다.
여기서 공분산 분석을 위한 두가지 가설을 제시할 수 있다.
- 가설 1: 종속변수에 미치는 공변량의 효과가 모두 동일해야 한다.
- 가설 2: 공변량의 효과는 0이 아니어야 한다.
공변량이 2개인 경우에 3개의 독립 변수가 있고, 종속변수를 y, 공변량을 x라고 했을 때 데이터 형태를 아래와 같이 표현할 수 있다.
| group1 | group2 | group(3) ... | |||
| $x_{11}$ | $y_{11}$ | $x_{21}$ | $y_{21}$ | $x_{31}$ | $y_{31}$ |
| $x_{12}$ | $y_{12}$ | $x_{22}$ | $y_{22}$ | $x_{32}$ | $y_{32}$ |
| $x_{13}$ | $y_{13}$ | $x_{23}$ | $y_{23}$ | $x_{33}$ | $y_{33}$ |
| : | : | : | : | : | : |
| $x_{1n_1}$ | $y_{1n_1}$ | $x_{2n_2}$ | $y_{2n_2}$ | $x_{3n_3}$ | $y_{3n_3}$ |
이 때 공분산모형은 다음 식과 같다.
$$y_{ij}=\mu+\alpha_i+\beta(x_{ij}-\bar x)+\epsilon_{ij}$$
$y_{ij}$: $i$번째 처리에서 $j$번째 개체의 반응 값
$x_{ij}$: 공변량
$\bar x$: 공변량 $x$의 전체 평균
$\mu$: 반응 변수 $y$의 전체 평균
$\alpha_i$: 변수의 효과
$\beta$: 모든 변수에 공통으로 작용하는 공변량의 효과
$\epsilon_{ij}$: 오차항
위에서 언급했던 가설 2개를 다시 한번 생각해보자. 수식으로 다시 설명해 볼 수 있는데,
- 가설 1: 종속변수에 미치는 $\beta$의 효과가 모두 동일해야 한다.
- 조산 출생이 백질 FA에 미치는 영향에 GA와 Age at MRI가 미치는 효과가 모두 같아야 한다.
- 가설 2: $\beta$의 효과는 0이 아니다.
- 이럴 경우는 ANOVA를 시행하면 된다.
One-way ANCOVA
일원공분산분석은 공변량이 하나일 경우 시행한다.
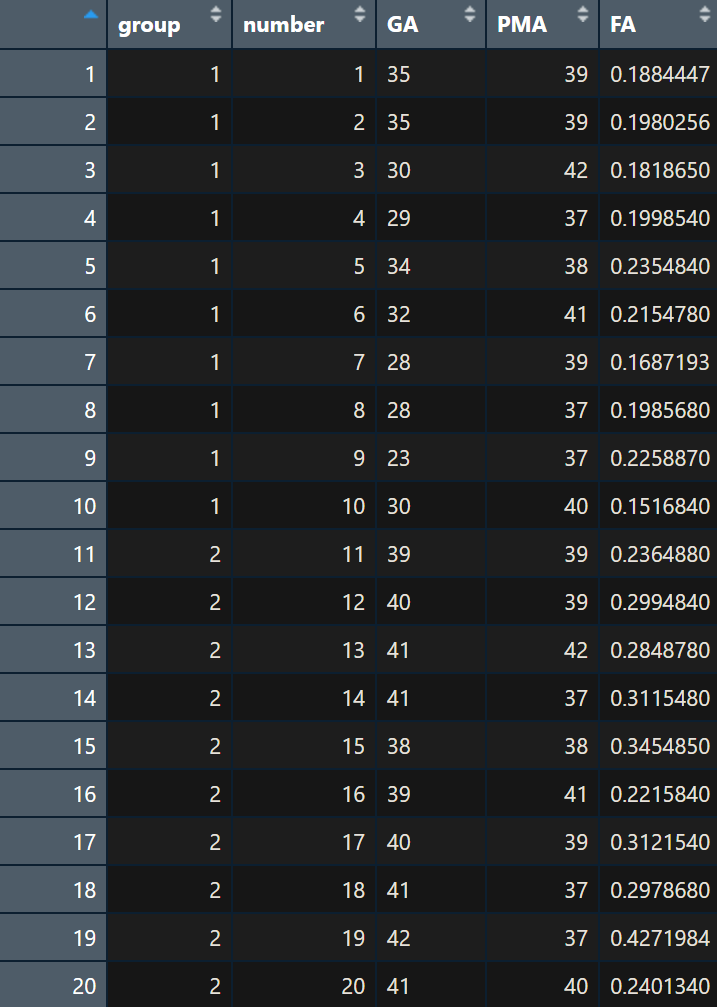
| <예제 1> 발달중인 신생아 20명에 대해 조산 출생과 정상 출생의 영향을 비교하고자 신생아 20명을 조산출생과 정상출생으로 나누어(2 그룹) 백질 성숙도 지표인 FA$(y)$를 측정하였다. 추가로 GA$(x)$가 FA$(y)$ 값에 영향을 미칠 것이라고 생각하여 GA$(x)$ 값도 함께 측정하였다. 여기서 조산출생과 정상출생의 차이가 있는지 검정하라. |
발달 중인 신생아 20명에 대한 조산군과 정상군(preterm, fullterm), GA$(x)$, FA$(y)$에 대한 데이터는 아래와 같다.
공분산 분석을 진행하기에 앞서 HH, Car, lsmeans를 설치하자.
먼저, 각 군에서 공변량 효과가 동일하다는 공분산 분석의 첫 번째 가정을 검정해 보자.
먼저 options 함수로 그룹의 계수의 합이 0이 되도록 지정해 보자.
options(contrasts=c("contr.sum","contr.poly"))(해당 R 코드를 사용하는 이유에 대해서는 차후 설명하겠습니다.)
각 군에서 공변량 효과가 동일한지를 확인하기 위해서는 그룹과 GA간의 상호작용 효과(Interaction effect)를 확인해야 한다.
상호작용이 존재한다면, 그룹간의 회귀계수가 동일하지 않다라고 해석할 수 있고, 공분산분석이 바람직 하지 않음을 시사한다.
model1 <- lm(`fa-value`~group*GA, data=FA)
Anova(model1, type="III")
Result
-------------------------------------------
Anova Table (Type III tests)
Response: fa-value
Sum Sq Df F value Pr(>F)
(Intercept) 0.000416 1 0.1965 0.6635
group 0.003045 1 1.4370 0.2481
GA 0.003980 1 1.8782 0.1895
group:GA 0.003952 1 1.8650 0.1909
Residuals 0.033904 16
-------------------------------------------
group:GA를 보면 상호작용에 대한 p값이 0.1909으로 유의수준 5%에서 유의하지 않음을 알 수 있다.
- 그룹과 GA 사이의 Interaction effect가 없음으로 공분산분석을 위한 첫 번째 가정을 충족한다.
ANCOVA의 경우는 Anova(model1, type="III")을 사용하여 분석하게 되는데, 여기서 제 1종 제곱합(Type I SS)과 제 3종 제곱합(Type III SS)에 대해서 훑고 넘어가보자.
먼저 제곱합에 대해 간략하게 정의하면,
- 제곱합(sum of squares, 자승합, SS)는 변동의 측정이나 평균의 편차를 나타내며, 평균과의 차이 제곱합으로 계산된다.
분산분석에서 제 1종 제곱합은
- 임의의 1차 상호작용 이전에 주효과가 지정되고 2차 상호작용 효과 이전에 1차 상호작용 효과가 지정되는 등의 균형분산 분석 모형으로 설명된다.
- 1차 지정 효과가 2차 지정 효과 내에 중첩되고 2차 지정 효과가 3차 지정 효과 내에 중첩되는 모형을 보인다.
- $Model SS$ = $SS(group, GA)$ = $SS(group) + SS(GA|group)$

제 1요인(group)이 FA에 값의 변화에 기여한 후에 제 2요인(GA)가 추가로 기여한 부분이다.
따라서 각 요인의 제 1종 제곱합은 요인들의 순서에 따라 값이 바뀔 수 있다.
3종 제곱합은 분산분석에서 기본값으로 사용되는 제곱합이다.
- 계획에 있는 한 효과의 제곱합을 계산할 때 이 효과를 포함하지 않는 다른 효과에 맞게 수정되며 이 효과를 포함하는 효과 (제 3의 효과)에 직교하는 제곱합 방법을 사용한다.
- 요인의 최종적인 기여분: $Model SS$ = $SS(group|GA) + SS(GA|group)$
- $SS(group|GA)$ = group의 제 3종 제곱합
- $SS(GA|group)$ = GA의 제 3종 제곱합

여기서 우리는 공변량의 효과를 제어했을 때 group에 따른 FA의 보정모평균이 차이가 나는지 여부가 궁금하기 때문에 group의 유의성은 제 3종 제곱합에 나타는 결과를 봐야 한다.
제 1종 제곱합과 제 3종 제곱합을 비교하여 보자
-----------------------------------------------------------------
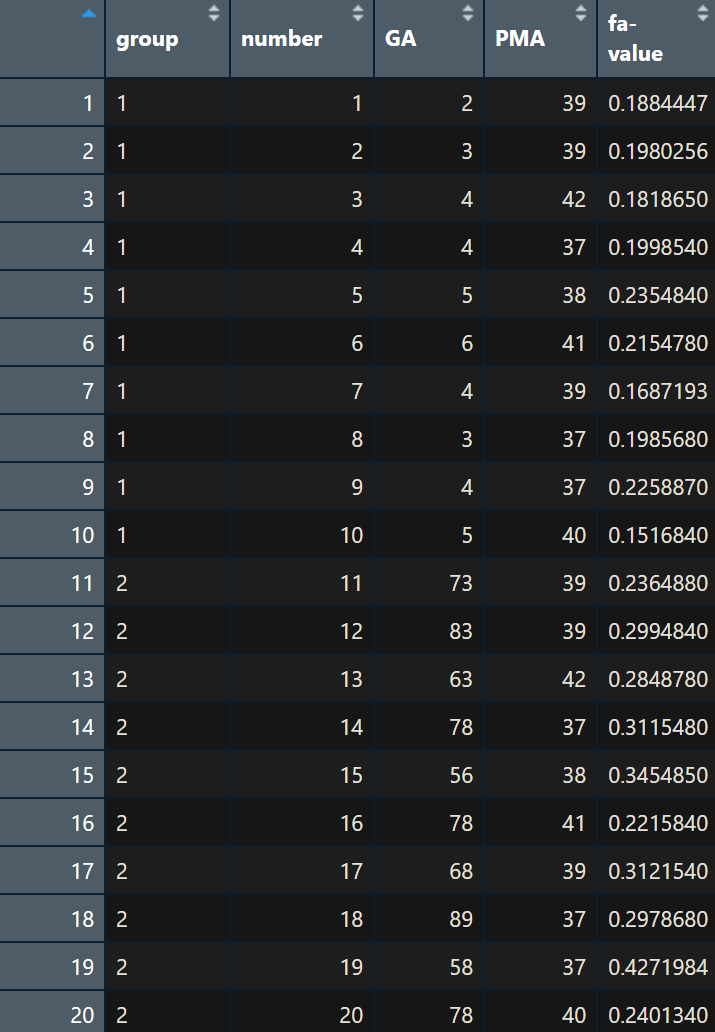
model2 <- lm(`fa-value`~group+GA, data=FA)
제 1종 제곱합
result
-----------------------------------------------------------------
> anova(model2)
Analysis of Variance Table
Response: fa-value
Df Sum Sq Mean Sq F value Pr(>F)
group 1 0.051289 0.051289 23.033 0.0001671 ***
GA 1 0.000441 0.000441 0.198 0.6619904
Residuals 17 0.037856 0.002227
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-----------------------------------------------------------------
제 3종 제곱합
result
-----------------------------------------------------------------
Anova Table (Type III tests)
Response: fa-value
Sum Sq Df F value Pr(>F)
(Intercept) 0.003799 1 1.7061 0.20889
group 0.007943 1 3.5672 0.07612 .
GA 0.000441 1 0.1980 0.66199
Residuals 0.037856 17
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-----------------------------------------------------------------해석
- group의 제 1종 제곱합의 p값은 0.001671로 유의하지만, 제 3종 제곱합의 p값은 0.7612로 유의하지 않다.
- group이 FA에 미치는 효과는 GA를 보정했을 때보다 보정하지 않았을 때 더 크다.
- GA에 대한 p값은 0.6619로 같게 나오는데, 두 제곱식에서 이 값은 $SS(GA|group)$가 동일하기 때문이다.
- p값이 5%에서 유의하지 않음으로 GA의 효과가 0이라는 귀무가설을 채택하게 된다.
- 즉, 공분산분석의 두 번째 가정이 불충족 되는 것을 볼 수 있다.
- GA는 공변량으로써 group간의 FA차이에 영향을 주는 요인이 아님을 밝힐 수 있다.
- 이러한 경우에는, ANOVA를 시행하면 된다.
두 번째 가설이 불충족 되었다고 공분산분석을 멈출수는 없다.
임의로 데이터를 수정하여 두 번째 가설이 충족하게끔 한 뒤 공분산 분석을 진행해 보고자 한다 (데이터가 변경되었어도 위에서 설명한 두개의 가설은 충족한다).
(여담이지만, 많은 논문들은 조산과 정상의 비교에 있어서 실제로 GA가 영향을 종속변수에 영향을 끼치지 않더라도 GA를 공변량으로 넣어 분석한다.)
제 1종 제곱합
result
-----------------------------------------------------------------
> anova(model2)
Analysis of Variance Table
Response: fa-value
Df Sum Sq Mean Sq F value Pr(>F)
group 1 0.051289 0.051289 30.4822 3.74e-05 ***
GA 1 0.009692 0.009692 5.7603 0.02812 *
Residuals 17 0.028604 0.001683
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-----------------------------------------------------------------
제 3종 제곱합
result
-----------------------------------------------------------------
> Anova(model2, type="III")
Anova Table (Type III tests)
Response: fa-value
Sum Sq Df F value Pr(>F)
(Intercept) 0.093167 1 55.3709 9.643e-07 ***
group 0.020678 1 12.2891 0.002711 **
GA 0.009692 1 5.7603 0.028123 *
Residuals 0.028604 17
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-----------------------------------------------------------------One-way ANCOVA (모형 적합성, 보정 평균, 다중 검정)
두 가지 가정이 모두 충족되었고 우리는 공분산분석을 시행할 수 있게 되었다.
------------------------------------------------------------------
> summary(model2)
Call:
lm(formula = `fa-value` ~ group + GA, data = FA)
Residuals:
Min 1Q Median 3Q Max
-0.059395 -0.030951 -0.001097 0.029778 0.086346
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.361563 0.048590 7.441 9.64e-07 ***
group1 -0.153170 0.043693 -3.506 0.00271 **
GA -0.002998 0.001249 -2.400 0.02812 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.04102 on 17 degrees of freedom
Multiple R-squared: 0.6807, Adjusted R-squared: 0.6431
F-statistic: 18.12 on 2 and 17 DF, p-value: 6.104e-05
------------------------------------------------------------------
해석
- 모형의 적합성을 보여주는 p값이 <.0001임으로 가정한 모형이 자료분석에 적합한 모형임을 확인할 수 있다.
- group1에 대한 p값은 group1과의 차이에 대한 유의성 검정으로 유의수준 0.05에서 group1과 group2에 유의한차이가 있음을 알 수 있다.
- ANCOVA의 경우에는 Adjusted R-squared: 0.6431을 봐야 한다.
- 독립변수를 추가할수록 결정계수가 1에 가까워진다는 단점을 보완한 보정된 결정계수이다.
- 즉, 적절하지 않은 독립변수를 추가한 모형이라면, 그것을 포함하지 않은 모형보다 작은 보정된 결정계수를 가진다.
공분산 모형식
각 출력된 추정계수(Estimate)를 바탕으로 공분산모형식을 작성할 수 있다.
- $\hat {y}_{1j}$ = $0.361563 + (-0.153170) + (-0.002998)x_{1j}$
- $\hat {y}_{2j}$ = $0.361563 + (0.361563) + (-0.002998)x_{2j}$
- 여기서 $\hat {y}$는 group이 많을 경우 표본의 $y$를 뜻한다. group이 많으면 더 많은 회귀식이 만들어 진다.
- 각각의 회귀식의 공변량에 공변량의 전체 평균값(mean GA: 38.2)를 곱하면 처리별 보정된 평균이 계산된다.
- $\bar {y}_{1j}$ = $0.361563 + (-0.153170) + (-0.002998)x_{1j} \cdot 38.2 = 0.0939$
- $\bar {y}_{2j}$ = $0.361563 + (0.361563) + (-0.002998)x_{2j} \cdot 38.2 = 0.4002$
- R에서 lsmeans() 함수를 통해 쉽게 구할 수 있다.
> LS <- lsmeans(model2, ~group)
---------------------------------------------
group lsmean SE df lower.CL upper.CL
A 0.0939 0.0446 17 -0.000322 0.188
B 0.4002 0.0446 17 0.306018 0.494
Confidence level used: 0.95
---------------------------------------------
다중비교 검정
group이 더 많다면 좋겠지만, 우선 2개 그룹이라도 각 그룹간의 비교를 위해 다중비교를 할 수 있다.
Tukey's HSD 검정을 시행해보자.
> model2.lsm=lsmeans(model2,pairwise~group,glhargs=list())
> print(model2.lsm,omit=1)
result
----------------------------------------------------------
$lsmeans
group lsmean SE df lower.CL upper.CL
A 0.0939 0.0446 17 -0.000322 0.188
B 0.4002 0.0446 17 0.306018 0.494
Confidence level used: 0.95
$contrasts
contrast estimate SE df t.ratio p.value
A - B -0.306 0.0874 17 -3.506 0.0027
----------------------------------------------------------해석
- HSD 검정에서 마찬가지로 p값이 유의수준보다 작기 때문에 두 그룹은 FA에 있어 유의한 차이가 있음을 다시 한번 확인할 수 있다 (A=group1; B=group2).
이를 신뢰구간을 포함한 그래프로 보여줄 수 있다
plot(model2.lsm[[2]]).

모형적합성 검토 결과
par(mfrow=c(2,2))
plot(model2)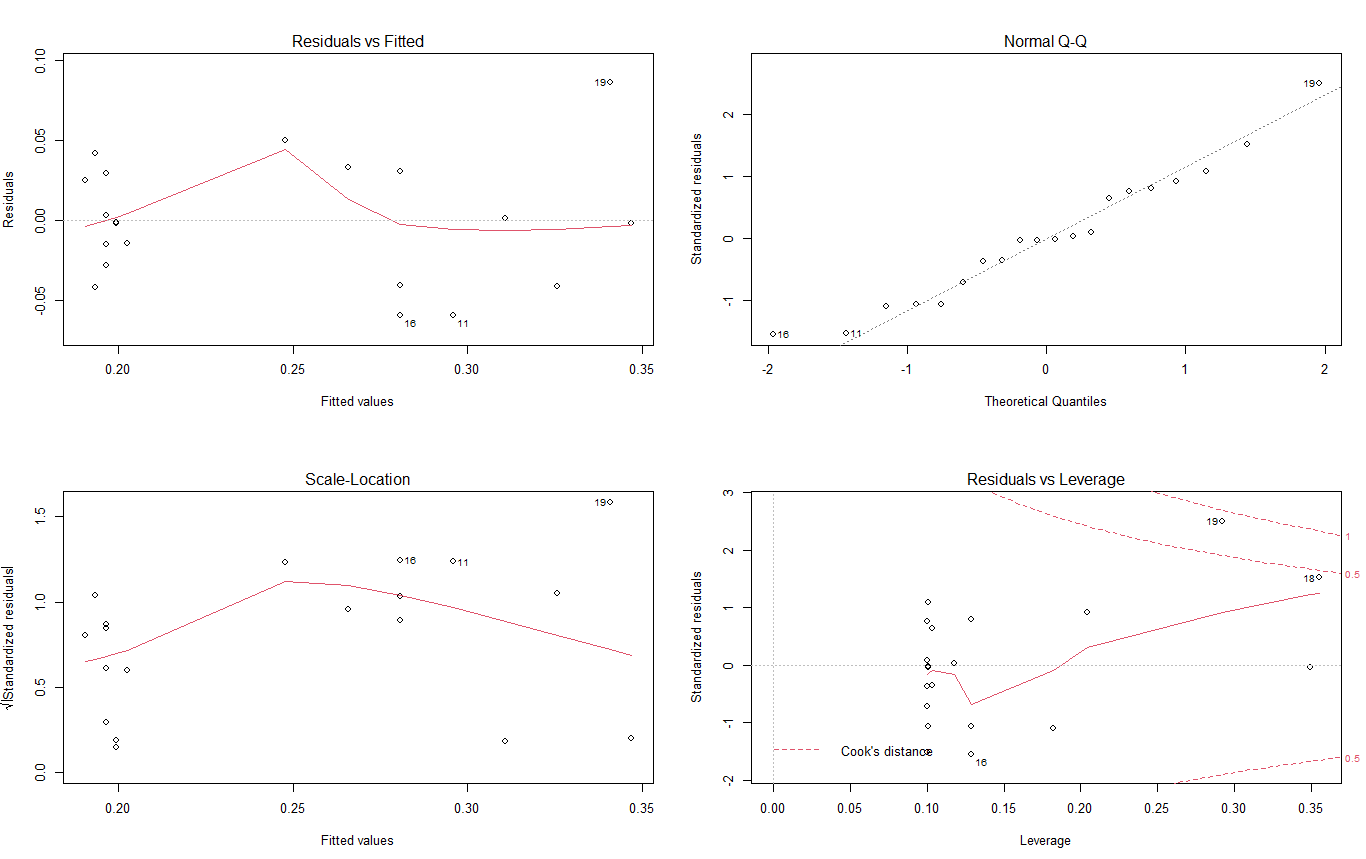
Two-way ANCOVA
to be continued...
Reference
https://blog.naver.com/PostView.naver?blogId=kunyoung90&logNo=222031709655&parentCategoryNo=&categoryNo=22&viewDate=&isShowPopularPosts=false&from=postView (이 곳에서 많은 소스를 얻어 저희 연구에 맞게 재구성하여 기술하였습니다. 저희 분석과 다른 분석을 진행하고자 하신다면, 즉 group이 많은 경우에는 해당 자료를 확인하세요.)
https://www.ibm.com/docs/ko/spss-statistics/SaaS?topic=model-sum-squares (제곱합을 알고 싶다면 여기로)
'통계 > 기초 통계' 카테고리의 다른 글
| 비모수적 상관분석 비교: Spearman's rho and Kendall's Tau (0) | 2022.06.28 |
|---|---|
| 다중공선성 (Multicollinearity) (0) | 2022.06.17 |