저작권 정보: Jang, Y. H., Kim, J., Kim, S., Lee, K., Na, J. Y., Ahn, J. H., ... & Lee, H. J. (2022). Abnormal thalamocortical connectivity of preterm infants with elevated thyroid stimulating hormone identified with diffusion tensor imaging.Scientific Reports,12(1), 1-11.
해당 저널은 Open access임을 사전에 밝힙니다.
한양대학교 소아과 이현주 교수 연구팀 논문
개요
갑상선 호르몬은 태아부터 출생 후 2-3년동안 뇌 발달에 필수적인 역할을 수행합니다. 조산의 갑상선 기능 장애의 원인은 아래와 같이 설명됩니다.
시상하부-뇌하수체-갑상선의 미성숙
갑상선 호르몬 합성과 대사의 손상
비갑상선 질환으로 인한 갑상선 호르몬 분비 증가
약물 투여
많은 연구들은 미숙아에서 특히 선천성 갑상선 기능 저하증(Congenital Hypothyroidism; CH)는 후기 신경발달장애의 원인이 될 수 있음을 밝혔습니다. CH의 임상 양상은 아래와 같이 표현됩니다.
발달지연
청력
언어
자발적 운동 활동
곁눈질
등의 신경학적 문제와 관련이 있습니다.
신생아 갑상선 검사 및 진단 기준
신생아 갑상선 검사는 출생 첫 주 갑상선 자극 호르몬(Thyroid-Stimulating-Hormone; TSH)와 유리 티록신( free Thyroxine; fT4)을 사용하여 수행됩니다. 여기서 조산아의 경우에는 첫 번째 선별검사에서 놓치 TSH 수치의 지연된 상승의 발생률이 높습니다. 그렇기 때문에 미숙아의 경우에는 TSH의 지연된 상승이 뇌 발달에 유의한 영향을 끼칠 수 있기 때문에 반복 검진을 강력하게 권고합니다.
지속적인 선별검사와 함께 신생아 갑상선 호르몬 검진의 TSH 절단 값 또한 신경 발달 장애를 예방하고 최적의 발달을 이루기 위해 고려되어야 합니다. 치료 기준
갑상선 기능 검사 $20mU/L$ 이상의 TSH 수준을 보이거나/보이면서 낮은 fT4 농도를 기반으로 합니다.
하지만,
TSH 수치가 $6$~$20mU/L$의 경우에는 치료 결정에 충분한 논의가 필요합니다.
그래서 많은 임상가들은 조산과 만삭 등가 연령(Term-equivalent age; TEA; 정상 출생 40주를 의미합니다.) 사이에 TSH 수치가 3-6주 이상 높게 유지될 경우 갑상샘 기능저하증의 약물요법으로 호르몬 제제인 levothyroxine을 처방합니다.
이렇듯 뚜렸한 진단 근거를 보이지는 않지만 뒤 늦게 급증하는 TSH와 같은 무증상 갑상선 기능 저하증(Subclinical Hypothyroidism; SH)은 신경 발달에 분명한 영향을 끼치고 후기 인지 기능 장애를 유발할 수 있습니다. 여기서 우리는 한가지 임상적 적용의 제한점을 제시합니다.
SH를 나타내는 초기 갑상선 기능 저하의 증상은 현저한 임상 증상으로 표현되지 않기 때문에 몇 주 안에 진단이 어렵습니다. 다시말하면, 미숙아에서 SH의 발병은 갑상선 기능 장애보다 먼저 발생합니다. 따라서 미숙아 신생아에서 SH의 합리적인 임상마커는 후기 신경발달을 예측하기 위해서 필요합니다.
우리는 SH의 합리적인 임상마커로 신생아 뇌 발달에 가장 중요한 지표중 하나인 시상 피질로(Thalamocortical pathway)의 발달을 탐구했습니다. 신생아 시기의 시상 피질로는 세계적인 학술지 Cerebral Cortex에서 메인 토픽으로 다룰 정도로 중요한 영역입니다. 시상 피질로에 대해 간략하게 설명해 드리면,
피질로는 대뇌 깊숙히 위치한 감각의 중개소인 시상(Thalamus)에서 대뇌피질(Cortex)로 이어지는 거대한 트랙입니다.
시상 피질로는 재태 연령 25주부터 TEA까지 빠르게 성장하여 기본적인 시각, 청각, 운동 및 체성감각 기능에 기여하는 주요 백질 조직입니다.
조산 시기에 시상 피질로의 손상은 의식, 작업, 기억, 감각 전달, 집행 및 통제에 장애를 일으킬 수 있습니다.
갑상선 자극 호르몬은 시상 피질로의 발달에 주축이 됩니다.
신경 이동, 신경교 세포의 증식, 시냅스 형성, 축삭 및 수상돌기 발다, 수초 형성
조산 시기에 갑상선 호르몬 기능 장애는 시상 피질로의 미성숙을 유발하여 앞서 설명한 신경발달적 장애를 유발 할 수 있습니다.
우리는 시상 피질로의 정량적 분석을 위해 뇌영상 분석을 진행하였습니다. 뇌영상 분석은 보다 정확한 지표를 추출하여 SH유발 이상을 조기에 예측할 수 있는 의미있는 바이오마커를 제공할 수 있습니다.
결과
결과에 앞서 연구 모델을 간략하게 기술하겠습니다.
36명의 조산(갑상선 호르몬 기능 정상) vs. 29명의 조산(갑상선 호르몬 기능 장애)
MRI 진단 소견상 이상이 없으며, 다른 합병증을 통제한 조산 출생 아동을 대상으로 하여 오롯이 호르몬 기능 장애가 조산아의 뇌 발달에 미치는 영향을 연구했습니다.
CN: 조산 호르몬 정상군; SH: 조산 호르몬 비정상군
그림 1. 시상에서 뇌의 다양한 피질로 향하는 시상 피질로 길이의 두 집단 차이를 보여줍니다.그림 2. 시상에서 뇌의 다양한 피질로 향하는 시상 피질로 길이의 두 집단 차이를 보여줍니다.
해석과 토의
그림 1과 2는 두 집안의 시상 피질로의 길이 차이를 보여줍니다. 해당 그림은 모두 시상에서 출발하여 각 피질(초록색)로 향하는 백질을 노랑~빨강으로 보여줍니다.
갑상선 기능이 정상인 조산 아동에 비해서 갑상선 기능 장애가 있는 조산 아동은 위에 나온 모든 영역에서 유의하게 저하된 뇌 섬유 길이를 나타냅니다.
SH가 있는 조산아의 전두엽, 측두엽 및 후두엽에서 시상 피질로의 섬유의 발달이 지연되었음을 나타내고, 위에서 설명하였듯이 비정상적인 백질 수초화 및 손상된 피질 성장을 반영합니다.
측두엽 발달 지연
이전 CH에 대한 연구에서는 특히 측두엽의 신경 세포 손실이 유아와 성인에서 피질이 얇아지는 현상으로 나타난다고 보고했습니다.
측두엽에서 섬유길이의 단축에 관한 우리의 결과는 피질이 얇아지는 것이 단축된 섬유와 양의 상관관계가 있다는 이전 연구로 뒷받침됩니다.
측두엽은 신생아 발달에서 언어와 청각인지에 중요한 역할을 수행하기 때문에 해당 영역은 신경 발달을 모니터링하기 위한 민감한 마커가 될 수 있습니다.
다른 영역의 발달 지연은 논쟁의 여지가 있어 추가 연구가 필요함을 밝힙니다.
결론
우리는 비침습적 DTI(MRI의 일종)을 사용하여 SH에서의 섬유 길이 감소를 밝혔으며, 이것이 조산아의 정상적인 발달을 위한 임상적으로 기능적이고 효율적인 치료를 지원할 수 있는 신뢰도 있는 이미징 바이오마커임을 암시합니다. 이전 연구에서 DTI를 통해 밝혀진 섬유의 이상은 조산아의 후기 정신, 인지, 언어 및 운동 기능과 양의 상관관계가 있기 때문에, 연속 갑상선 검사와 함께 DTI를 통한 섬유질 변화의 추적은 조산아가 갑상선 호르몬 치료를 받는 동안 대뇌 발달이 잘 이루어 지는지 확인할 수 있는 정량적 임상 바이오마커로 활용될 수 있습니다.
범주형 변수의 수준(level) 간에 종속변수의 평균에 차이가 존재하는가 를 분석한다 (ANOVA)?
여기에 종속변수에 영향을 미칠 것으로 판단되는 연속형 변수, 범주형 변수(공변량: covariate)의 효과를 동시에 고려하여 분석한다.
정리하면, 각 변수 안에서 공변량을 독립변수로 하는 회귀분석을 시행하고, 이것으로부터 얻어진 변수 간 회귀식을 분산분석한다.
공분산분석의 목적
공변량을 통제하여 독립변수의 순수한 영향을 검정하기 위함이다.
ANOVA에 통제할 수 없는 연속형 변수를 통제하여 오차를 줄이고 검정력을 높인다.
공분산분석 (출처: https://bioinformaticsandme.tistory.com/198); 주요 독립 변수를 중점으로 두고, 나머지 독립 변수를 공변량으로 분석할 수 있다.
공분산분석의 가정
정상출생아와 조산 출생아의 뇌 발달 차이를 검정하고자 할 때,
가설: 두 그룹간 백질 성숙도의 차이가 있을 것이다.
여기에, 우리는 백질의 분획이방성(fractional anisotropy; FA)에 순수하게 조산 출생의 여부가 미치는 영향을 보고 싶다. 그렇지만, 종속변수인 FA에 신생아의 재태 기간(Gestational age; GA) 혹은 MRI를 찍은 주수(Age at MRI; 신생아 뇌 발달은 급격하게 이루어 지기 때문에 MRI를 찍은 주수가 백질 발달에 영향을 충분히 미칠 수 있다)에 따라 FA가 영향을 받을 수 있다. 그렇기 때문에 우리는 GA와 Age at MRI를 종속변수 FA에 영향을 미칠 것으로 판단하여 covariate로 지정할 수 있다.
우리는 성별과 Age at MRI가 두 그룹의 FA에 동일하게 영향을 미치는가에 대하여 질문할 수 있다.
여기서 공분산 분석을 위한 두가지 가설을 제시할 수 있다.
가설 1: 종속변수에 미치는 공변량의 효과가 모두 동일해야 한다.
가설 2: 공변량의 효과는 0이 아니어야 한다.
공변량이 2개인 경우에 3개의 독립 변수가 있고, 종속변수를 y, 공변량을 x라고 했을 때 데이터 형태를 아래와 같이 표현할 수 있다.
조산 출생이 백질 FA에 미치는 영향에 GA와 Age at MRI가 미치는 효과가 모두 같아야 한다.
가설 2: $\beta$의 효과는 0이 아니다.
이럴 경우는 ANOVA를 시행하면 된다.
One-way ANCOVA
일원공분산분석은 공변량이 하나일 경우 시행한다.
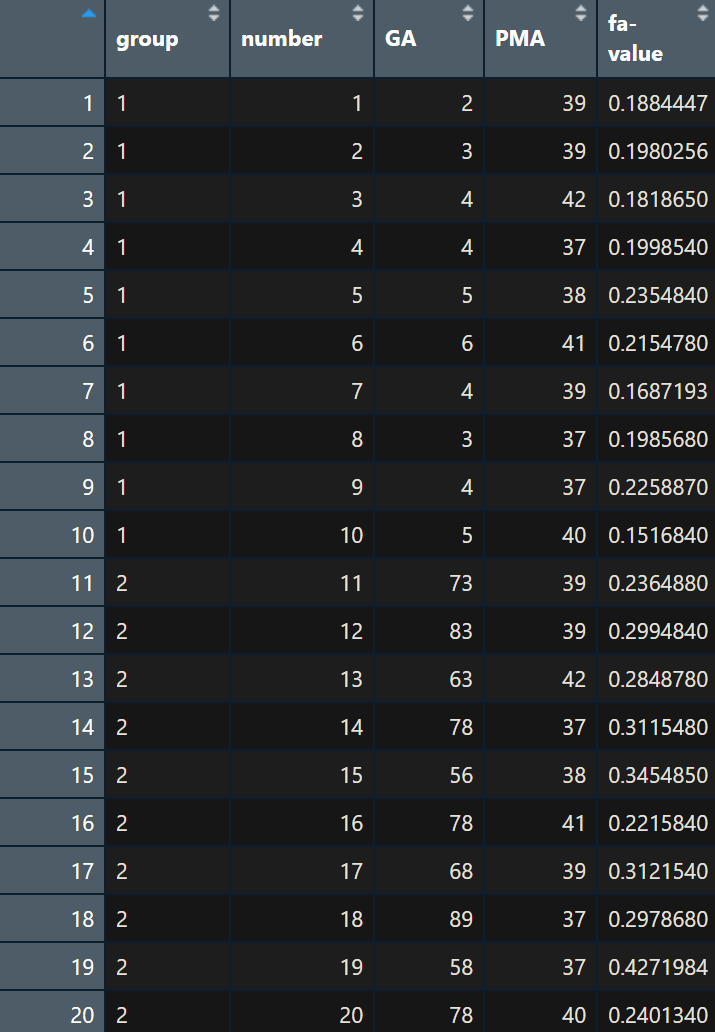
<예제 1> 발달중인 신생아 20명에 대해 조산 출생과 정상 출생의 영향을 비교하고자 신생아 20명을 조산출생과 정상출생으로 나누어(2 그룹) 백질 성숙도 지표인 FA$(y)$를 측정하였다. 추가로 GA$(x)$가 FA$(y)$ 값에 영향을 미칠 것이라고 생각하여 GA$(x)$ 값도 함께 측정하였다. 여기서 조산출생과 정상출생의 차이가 있는지 검정하라.
발달 중인 신생아 20명에 대한 조산군과 정상군(preterm, fullterm), GA$(x)$, FA$(y)$에 대한 데이터는 아래와 같다.
FA, fractional anisotropy; GA, gestational age; PMA, age at MRI; group1, preterm infants; group2, full-term infants.
공분산 분석을 진행하기에 앞서 HH, Car, lsmeans를 설치하자.
먼저, 각 군에서 공변량 효과가 동일하다는 공분산 분석의 첫 번째 가정을 검정해 보자.
먼저 options 함수로 그룹의 계수의 합이 0이 되도록 지정해 보자.
options(contrasts=c("contr.sum","contr.poly"))
(해당 R 코드를 사용하는 이유에 대해서는 차후 설명하겠습니다.)
각 군에서 공변량 효과가 동일한지를 확인하기 위해서는 그룹과 GA간의 상호작용 효과(Interaction effect)를 확인해야 한다.
상호작용이 존재한다면, 그룹간의 회귀계수가 동일하지 않다라고 해석할 수 있고, 공분산분석이 바람직 하지 않음을 시사한다.
model1 <- lm(`fa-value`~group*GA, data=FA)
Anova(model1, type="III")
Result
-------------------------------------------
Anova Table (Type III tests)
Response: fa-value
Sum Sq Df F value Pr(>F)
(Intercept) 0.000416 1 0.1965 0.6635
group 0.003045 1 1.4370 0.2481
GA 0.003980 1 1.8782 0.1895
group:GA 0.003952 1 1.8650 0.1909
Residuals 0.033904 16
-------------------------------------------
group:GA를 보면 상호작용에 대한 p값이 0.1909으로 유의수준 5%에서 유의하지 않음을 알 수 있다.
그룹과 GA 사이의 Interaction effect가 없음으로 공분산분석을 위한 첫 번째 가정을 충족한다.
ANCOVA의 경우는 Anova(model1, type="III")을 사용하여 분석하게 되는데, 여기서 제 1종 제곱합(Type I SS)과 제 3종 제곱합(Type III SS)에 대해서 훑고 넘어가보자.